huggingface-hub的几个bug的解决方案记录
Update: 本文提的 Issue 在 huggingface-hub 的main分支已解决,暂未发版,大家可以手动安装main分支版本。
huggingface-hub 目前对于 HF_ENDPOINT 的支持存在几个 bug,已经给官方提了 issue,在修复前,先记录下临时解决方案。
好奇宝宝
Update: 本文提的 Issue 在 huggingface-hub 的main分支已解决,暂未发版,大家可以手动安装main分支版本。
huggingface-hub 目前对于 HF_ENDPOINT 的支持存在几个 bug,已经给官方提了 issue,在修复前,先记录下临时解决方案。
Update: 推荐 huggingface 镜像站: https://hf-mirror.com
Update: 推荐官方的 huggingface-cli 命令行工具、以及本站开发的 hfd脚本。
本文已发表至知乎 https://zhuanlan.zhihu.com/p/663712983。
Stackoverflow 上有个AI开发入门的最常见问题 How to download model from huggingface?,回答五花八门,可见下载 huggingface 模型的方法是十分多样的。
其实网络快、稳的话,随便哪种方法都挺好,然而结合国内的网络环境,断点续传、多线程下载等特性还是非常有必要的,否则动辄断掉重来很浪费时间。基于这个考虑,对各类方法做个总结和排序:
| 方法类别 | 推荐程度 | 优点 | 缺点 | |
|---|---|---|---|---|
| 基于URL | 浏览器网页下载 | ⭐⭐⭐ | 通用性好 | 手动麻烦/无多线程 |
| 多线程下载器 | ⭐⭐⭐⭐ | 通用性好 | 手动麻烦 | |
| CLI工具 | git clone命令 |
⭐⭐ | 简单 | 无断点续传/冗余文件/无多线程 |
| 专用CLI工具 | huggingface-cli+hf_transfer |
⭐⭐⭐ | 官方下载工具链,功能最全 | 无进度条/容错性低 |
huggingface-cli |
⭐⭐⭐⭐⭐ | 官方下载工具 | 不支持多线程 | |
| Python方法 | snapshot_download |
⭐⭐⭐ | 官方支持,功能全 | 脚本复杂/无多线程 |
from_pretrained |
⭐ | 官方支持,简单 | 不方便存储,功能不全 | |
hf_hub_download |
⭐ | 官方支持 | 不支持全量下载/无多线程 |
另外对于数据集的下载和模型基本相同,同理参考。
以下对上述方法进行介绍,并介绍几个常见问题:
今年五月份,看到了第二届法研杯的比赛介绍,是个法律NLP的竞赛,由于所在公司也是做的法律领域,就用些业余时间做了一下。这也是我第一次参加比赛,最后获得了总榜第二名的成绩,现在把一些比赛经历和心得记录一下。
项目代码见 https://github.com/padeoe/cail2019,报告会 PPT下载链接。
关于比赛 Read More.
本文提供 另一个 html 版本。
Bert 是 Google 在 2018 年 10 月提出的一种新的语言模型,全称为 Bidirectional Encoder Representations from Transformers(Bert)。和近年来的一些语言模型譬如 ELMo 不同,BERT 通过在所有层联合调节左右两个上下文来预训练深层双向表示,此外还通过组装长句作为输入增强了对长程语义的理解。Bert 可以被微调以广泛用于各类任务,仅需额外添加一个输出层,无需进行针对任务的模型结构调整,就在文本分类,语义理解等一些任务上取得了 state-of-the-art 的成绩。
Bert 的论文中对预训练好的 Bert 模型设计了两种应用于具体领域任务的用法,一种是 fine-tune(微调) 方法,一种是 feature extract(特征抽取) 方法。
wordpress的markdown生成的格式不是很好看,本文另外一个html版 。
本文就是个读书笔记,建议读者阅读文末参考文献2和3,比本文不知高到哪儿去了。
被称为理性主义方法,主要依赖于人的总结。基于人工整理的 CFG (上下文无关文法,Context-Free Grammar) 规则,给出解决方案。
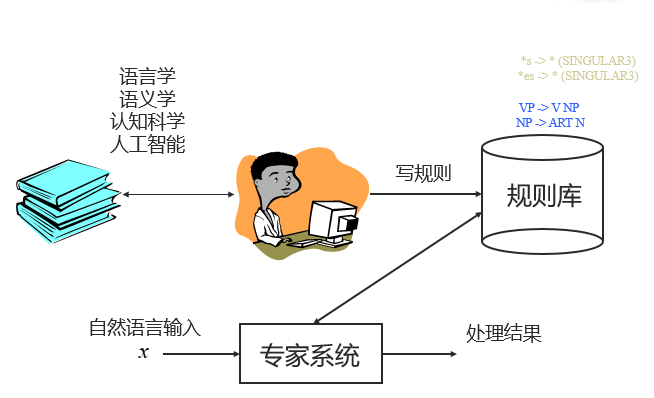
被称为经验主义方法,主要依赖于对数据的总结。从数据入手,利用统计机器学习方法解决问题。例如:通过自动学习得到PCFG(概率上下文无关文法),通过概率模型预测句法分析结果。
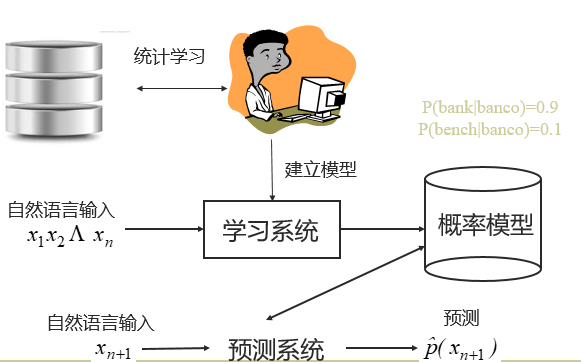
我们主要采用统计方法来进行机器学习。因此 统计自然语言处理的基本套路: – 问题形式化:将歧义问题转换成分类预测问题 – 语言的表示,建模:譬如n元模型 – 参数训练方法 – 有效的解码、推断
统计语言模型(Statistical Language Model)是一种History-based Model。 P(W)=P(w1w2…wn)=P(w1)P(w2|w1) 定义:统计语言模型是用来刻画一个句子(词串序列)存在可能性的概率模型
P(w3|w1w2)…P(wn|w1w2…wn-1)
该模型认为,语句中当前词是可以通过之前的词预测的。当然这个假设其实有些不切实际的,因为不可能总是通过过去的词预测将来的词。