法研杯2019相似案例匹配亚军经验分享
今年五月份,看到了第二届法研杯的比赛介绍,是个法律NLP的竞赛,由于所在公司也是做的法律领域,就用些业余时间做了一下。这也是我第一次参加比赛,最后获得了总榜第二名的成绩,现在把一些比赛经历和心得记录一下。
赛题简介
项目代码见 https://github.com/padeoe/cail2019,报告会 PPT下载链接。
关于比赛和赛题详情参见比赛官网和官方 Github 链接。简要来说,是一个法律文书相似度计算问题,所有文书来自裁判文书网的真实借贷纠纷案件。问题形式是给定三个文书(A, B, C),预测A与B, C中的哪一个更为相似,评价指标是准确率。
第一阶段的尝试
拿到赛题第一步尝试就是用BERT做了一个最简单的分类任务:
将三段文本ABC拼接起来,然后直接输入BERT做分类任务,在huggingface的pytorch-pretrained-BERT的run_glue.py的基础上quick hack的,其中mask embedding对a、b、c分别标记为0、1、0,将句子对输入改成了句子三元组输入,并且还要修改句子拼接裁切的部分,把超出512的部分裁切掉,裁切策略可以看到BERT官方代码写了一个句子对启发式的裁切方案,对a、b交叉获取字符输入队列直至队列满512,而非拼接后从一端裁切或者a、b分别裁切,这样可能某篇文书会被裁过度。具体可以看BERT官方代码。我还尝试了前向截取和后向截取,发现还是后向截取效果较好,说明文书的尾部有更多有效信息,这个方案也保持到了比赛最后。
很快就跑出了结果,得分79分,已经超过比赛baseline的62.88分。不得不感叹BERT的强大,因为三个句子的总长在1000字符以上,仅用其中512个字符竟然可以一战。这个尝试加强了我用BERT继续做比赛的基调,整个第一阶段保持在了TOP 10。
第二个尝试的模型就是为了解决BERT输入超长的问题,基于刚才的BERT修改,很快尝试了两个方案:
第一个就是孪生网络方案,将A、B、C分别输入BERT,每次输出768维度,将三个输出拼接成一个 768*3 的向量。对拼接向量进行接线性层分类。这样每篇文书都可以最长输入512个字符,得分有很大的提升,辅以一通神秘调参,得分85分左右。
孪生网络有一个很大的问题,就是对于输入的交互建模较差,而我们的比赛任务则是要比较AB、比较AC,因此AB之间的交互、AC之间的交互一定很重要,因此做了一个改进,将AB拼接作为一个输入、AC拼接作为一个输入,输入到BERT,同样是孪生网络,AB、AC由于具有对称性,比较适合孪生网络,如此一设计,模型性能确实有很大提升,最终可以得分88分的成绩。
还要介绍一下关于数据处理方面的问题。第一阶段的训练样本仅有500条,样本太少导致准确率低,且k折交叉准确率方差很大,因此数据增广很有必要。
我们将比赛的训练记作 (A,B,C),0 的形式,用 0 表示文书 A 与 B 更相似,1 表示文书 A 与 C 更相似。那么我们可以根据相似案例三元组的一些性质做增广,我们设计了如下几种增广:
| 序号 | 描述 | 增广产物 |
|---|---|---|
| 1 | 反对称增广 | (A,C,B), 1 |
| 2 | 自反性增广 | (C,C,A), 0 |
| 3 | 自反性+反对称 | (C,A,C), 1 |
| 4 | 启发式增广 | (B,A,C), 0 |
| 5 | 启发式增广+反对称 | (B,C,A), 1 |
最终性能提升:
| 方法 | 准确率(5-折交叉平均) |
|---|---|
| 反对称增广 | 0.788 |
| 反对称+启发式增广 | 0.784 |
| 反对称+自反性增广 | 0.810 |
| 反对称+启发式+自反性增广 | 0.852 |
其中的所谓启发式增广是我拍脑袋想出来并验证有一定效果的增广,理论上(A,B,C),0表明,sim(A,B)>sim(A,C),并不能表明sim(B,A)>sim(B,C),但是我想标注者构造样本时,有可能会引入一些信息泄露,会不会选定A、B后,不仅会选择一个和A不相似的C,更进一步会选择一个和A、B都不相似的C,因此导致该增广会成立?实际测试第一阶段也是有效果的,另外可能带来了数据量增多,模型的方差也降低了。
第二阶段的尝试
第二阶段主办方给出了5000条训练集,第一阶段的模型已经可以跑出相当好的成绩了,保持在了前三名的成绩,除了调参之外,对模型做了一个修改,形成的最后模型结构如下:
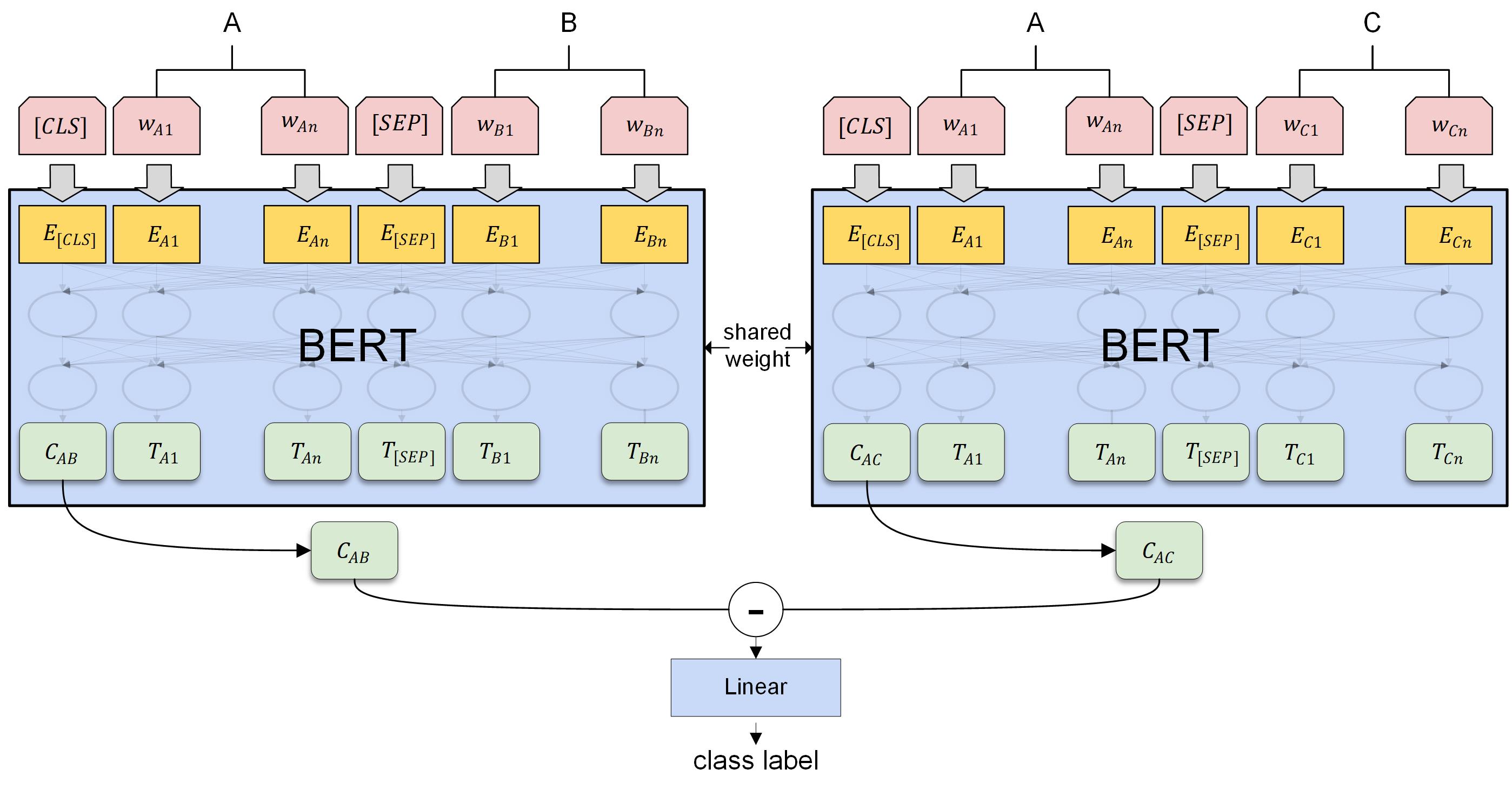
首先,模型是一个孪生网络的结构,使用了两个共享权重的 BERT 模型,分别将 AB 和 AC 输入 BERT,将对应的 [CLS] 取出,并做一个相减运算,最后拼接一个线性层输出后进行分类,使用交叉熵计算二分类损失。
模型可以这么理解,我们认为通过模型监督任务的设计, BERT 输出的 [CLS] 可以学习出每次输入的两个句子在各种不同维度上的相似度情况,因此 Cab、Cac分别表示了 AB 的相似度,AC 的相似度,最终将两者相减,就可以对比出在各种不同维度上 AB 相似度更高还是 AC 相似度更高,最终线性层则是对这些维度进行加权,得出一个综合的相似度判定。这里的相减,相比于第一阶段的拼接,会有将近一个点的提升。
对比其他选手的集成模型,我们仅用如上设计的单模型就取得了相当好的效果。
尝试的其他方法
除了以上的方案以外,我和队友还尝试了其他的一些方法,虽然最后没有用上,但大致还是记录一下。主要针对该问题的以下难点进行了尝试:
文本过长
因为bert的输入文本限制长度不超过512,我们之前的解决方案选择了从后截断。这样做丢失了一些信息。(注:其他组基于textCNN的解决方案利用了全部输入,可能这是他们能有接近bert得分的原因之一)
自然的改进思路是能不能把全部文本的信息传给模型。
尝试1: 对文本分别做position encoding编码。bert限制文本输入长度不超过512的直接原因就是其用来训练的所有样本长度都\<512,而bert使用的position encoding是直接按位置编码的,故不能外推至长度超过512的文本。
我们尝试了将两个句子分别做position encoding,这样结合segmentation mask BERT应该仍然能还原出完整的位置信息。 实验结果: 两段文本各自长度不超过256时,模型可以收敛,效果差于常规position encoding。两段文本长度超过256时(实验了300,384,512),模型不收敛。
尝试2: 将文本从中间截断,分别传给两个bert模型,最后拼接FC层输出。 效果差。
尝试3: 把切分位置不同的样本放入数据集中一起训练(未作测试时增强)。效果差。
尝试4:用BERT模型的feature based方法提取句子的特征,传给LSTM,效果差,可能改用CNN+ ESIM会有效果。
法律文本的特殊性
法律文本是一种特殊的文本,尤其是本问题中遇到的借贷纠纷文本,其中的数字如金额,利率,日期均具有重要语义。同时,法律文本是有结构的,他一般分为原被告-诉求-事实-本院认定这4个段落,直接训练神经网络难以识别到这些数字和结构特征。一种可能的想法就是通过特征工程提取出这些数字特征和神经网络相结合以提升效果。
通过简单的正则表达式,我们提取了案件中的金额,利率,案发时间,各段落长度等特征,并:
- 做了特征的交叉,训练了一个lightgbm模型。二阶段CV得分63.2左右,比BERT模型低3-5个百分点的准确率。令人惊讶的是,该模型和BERT的预测结果的相关性只有0.44左右,这说明两个模型学到的内容相当不同。但是最终集成没有效果。
- 直接归一化后在FC层拼接BERT encoder的输出进行fine-tuning,没有效果。直接使用这些特征训练神经网络也不行,可能是是神经网络需要别的处理方法。
- 三元组的问题形式
- 我们提交的解决方案里的模型实际上是分别对两对文书的相似性进行建模再比较,这不是唯一的建模方式。例如冠军就使用了
triplet margin loss进行训练。不知道为什么我们直接用这个损失函数训练时模型不收敛。 - 三元组每次前向需要推断两次BERT,训练会很慢。一种想法就是能不能把标签标记到二元组,即直接用一对文书的相似度做
训练,这样样本效率更高,推断会快些。一种简单的想法就是直接认为三元组中的AB相似度为1,AC相似度为0,但是这种做法显然是有问题的,会产生标记冲突的样本。我们尝试了计算出符合三元组标记关系的软label,
并要求这个软label和BERT原始模型的预测值相差不大。用软label训练的模型性能略差于提交解决方案里的BERT模型,但是训练要快些。最终两个模型的集成没有效果。
- 我们提交的解决方案里的模型实际上是分别对两对文书的相似性进行建模再比较,这不是唯一的建模方式。例如冠军就使用了
一些感想
- BERT的能力和潜力还是很大的
- 和其他选手的交流发现,长文本处理或许CNN还是可以试一试的。BERT最多处理512字符的限制了其对长文本的能力。
- 一些做法无效可能还是实验问题,譬如triplet loss看很多选手使用了,但我们使用无效。
- 特征工程还是有一定作用的。
- 最终有效的方案没有用上集成还是很遗憾的。做集成需趁早,到第三阶段才做结果时间来不及了。
大致总结如上,期望大家的批评指正和交流。
共有 0 条评论