wordpress的markdown生成的格式不是很好看,本文另外一个html版 。
本文就是个读书笔记,建议读者阅读文末参考文献2和3,比本文不知高到哪儿去了。
自然语言处理的概念
自然语言处理的两大途径
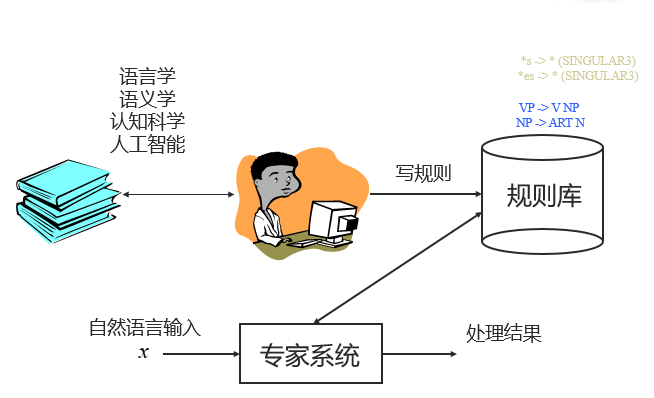
规则方法
被称为理性主义方法,主要依赖于人的总结。基于人工整理的 CFG (上下文无关文法,Context-Free Grammar) 规则,给出解决方案。
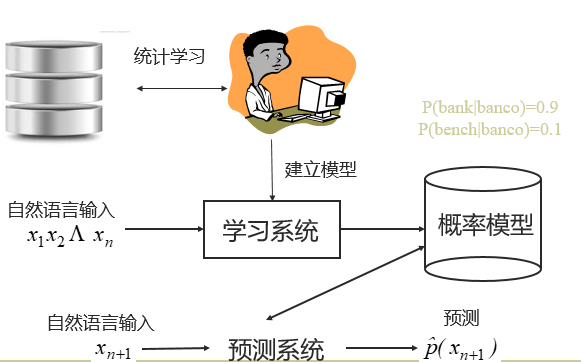
统计方法
被称为经验主义方法,主要依赖于对数据的总结。从数据入手,利用统计机器学习方法解决问题。例如:通过自动学习得到PCFG(概率上下文无关文法),通过概率模型预测句法分析结果。
统计自然语言处理(Statistical NLP)
我们主要采用统计方法来进行机器学习。因此 统计自然语言处理的基本套路: – 问题形式化:将歧义问题转换成分类预测问题 – 语言的表示,建模:譬如n元模型 – 参数训练方法 – 有效的解码、推断
自然语言处理的基本框架
n元模型
统计语言模型
统计语言模型(Statistical Language Model)是一种History-based Model。 P(W)=P(w1w2…wn)=P(w1)P(w2|w1)
P(w3|w1w2)…P(wn|w1w2…wn-1) 定义:统计语言模型是用来刻画一个句子(词串序列)存在可能性的概率模型
该模型认为,语句中当前词是可以通过之前的词预测的。当然这个假设其实有些不切实际的,因为不可能总是通过过去的词预测将来的词。
Read More.