深度森林
本文是 MLA2017会议上周志华关于深度森林报告的一个笔记。本文的另一个 html 版本。周志华老师花了很大一部分时间谈了谈深度森林背后的一些思考,受益良多。会议 ppt 在 MLA官网。
首先,周志华回顾了深度学习的一些基本问题
深度学习是什么?
Deep Learning =? Deep neural networks (DNNs)
当今的深度学习,当前几乎等同于深度神经网络(DNNs)。就是把神经网络的层数加深。周志华认为深度学习的内涵需要思考以下问题
1.神经网络为何要加深
对于神经网络,提升模型复杂度可以提高学习性能。当然,复杂度提高之后一方面容易出现过拟合,因此深度学习同时需要提升数据量。另一方面训练过程变得困难,因此需要很多 tricks 。
但是有一个基本问题就是,如何提升模型复杂度?
对于一个神经网络,提升复杂度有两种方式,一种是加宽(即增加每一层的 unit 数量),一种是加深(增加 layer 数量)。那就有一个问题了,为什么我们选择变深而不选择变宽?
2.神经网络为何选择变深而非变宽?
单隐层神经网络可以被证明能够逼近函数,因此加宽也可以让模型复杂度可以变得无限高。但是加宽之后效率很低,加深带来的性能提升则明显很多。
那是否可以有可能设计出一种在网络宽度上做文章的模型?周志华认为,要回答这个问题,就要思考深度学习为什么能行这个问题
3.深度模型为什么能行(为什么效果好)?
周志华认为,深度模型有三个重要的方面:
- 逐层加工(Layer-by-layer processing)
- 特征变换(Feature transformation)
- 足够的复杂度(Sufficient model complexity)
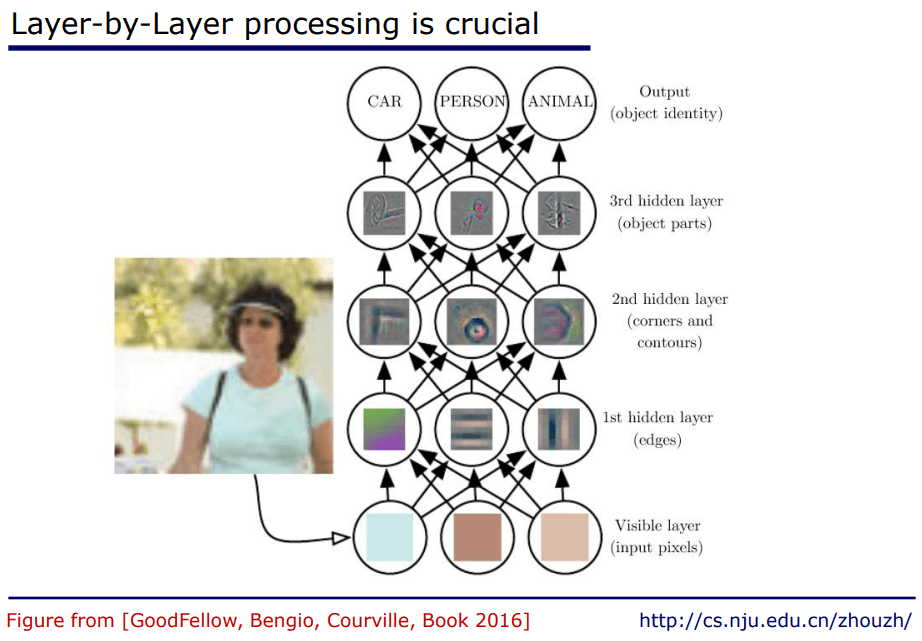
譬如图像识别过程。
其实传统机器学习方法例如决策树就是逐层加工的,但是缺乏足够的复杂度。那么采用集成方法的可以提升复杂度,譬如Boosting方法,但是还是不够复杂,因为没有特征变换过程,总是在同样的特征空间进行处理。
4.深度神经网络有何缺点?
- 超参数太多,调参trick很难操作导致,不同的人员调参获得的结果不同,很难重复
- 模型的结构一旦决定,复杂度就固定了,然而我们通常在训练开始之前确定网络结构,因此不能动态调整网络复杂度,导致很多时候模型过度复杂。
- 需要大量数据(防止过拟合)
- 理论分析很难/黑盒
此外,在很多任务上DNN效果并不一定好,譬如在许多 Kaggle 竞赛任务上,最后是机森林和 XGBoost 获胜。
另外,深度神经网络的训练通过BP算法,要求任务是连续可微的,离散任务变成连续再训练的过程会引入bias。
深度森林
接下来,周志华先简单介绍了深度森林: 一言以蔽之,深度森林是一种集成学习算法。一些细节:
- 名称问题:gcForest (multi-Grained Cascade Forest) 读音类似 “geek forest”
- 是一种决策树森林(集成)方法
- 在大量任务上可以和 DNNs 抗衡
- 更少的超参数
- 容易设置
- 在大量任务上默认参数就运行的很好
- 自适应的模型复杂度
- 根据数据自动决定复杂度
- 可用于小数据集
因此,要了解深度森林,要先了解集成学习。
集成学习:如何得到一个好的 ensemble ?
每个个体不同且每个个体不能太坏!
- 个体性能
- 个体多样性 (diversity)
根据 Error-ambiguity decomposition (错误-多样性分解)[Krogh & Vedelsby, NIPS’95],理论证明了如下公式: 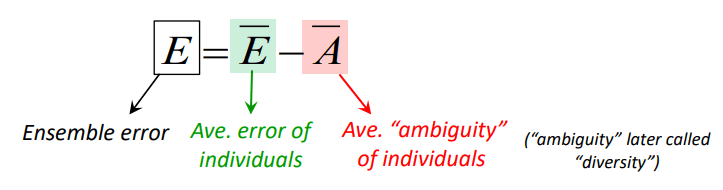 也就是 Ensemble 的总体错误率等于每个学习器个体的平均错误率减去学习器多样性。
也就是 Ensemble 的总体错误率等于每个学习器个体的平均错误率减去学习器多样性。
所以说,diversity非常重要。
当然以上公式只有在使用均方误差的回归任务中可以推导出来,周志华认为虽然只有在这种情况下才能写出这样漂亮的公式,但是也对通用的 ensemble 方法有指导意义。
如何产生 diversity ?
主要有四种方法:
- 数据样本扰动
- 例如 Bagging 里的 bootstrap 采样,Boosting 里的 importance 采样
- 输入的特征扰动
- Random Subspace 里的特征采样
- 学习参数扰动
- NN 里的随机初始化
- 负相关(Negative Correlation)
- 输出表示扰动
- ECOC
- Flipping Output
级联森林(Cascade Forest)
深度森林(multi-Grained Cascade Forest)是一种级联森林(Cascade Forest)结构。如下图所示。
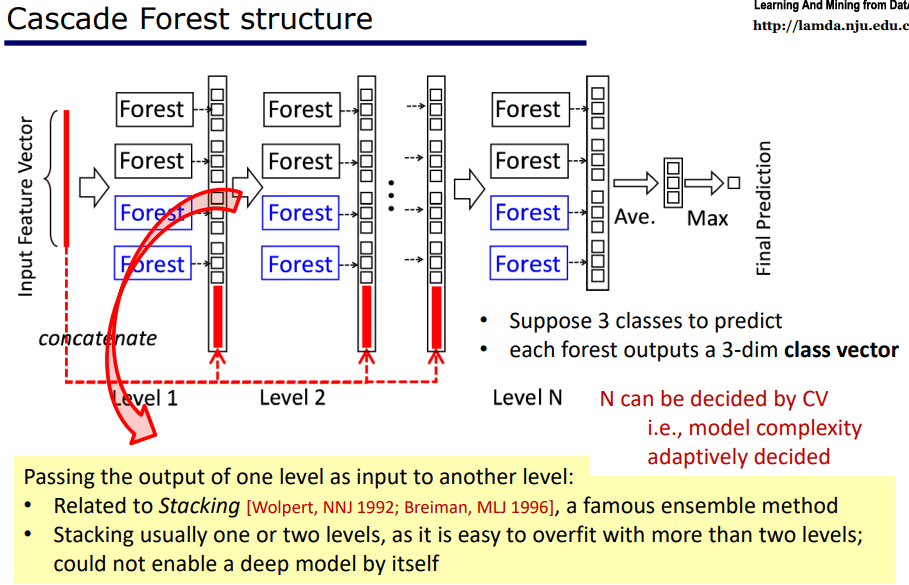
注意图中的Forest,指的是随机森林,而蓝色的Foreset,指的是完全随机森林(Completely-random trees),是为了提供更强的 diversity。
观察图中结构,假设我们在做一个三分类任务,那我们每一层每一个随机森林都输出一个三维向量,输出每一类的预测概率。并把同一层所有的输出拼接起来送到下一层作为输入,同时值得注意的是,我们不仅把这一层的输出,还把最原始的数据也一起拼接起来,这样我们就做了一次特征变化,并保留了原始特征继续后续处理,每一层都这样,最后一层将所有随机森林输出的三维向量加和求平均算出最大的一维作为最终输出。
集成方法的集成
上面的级联森林结构中使用了多个集成方法:
- 首先,随机森林就是一种集成式随机树方法,每一棵树考察根号 d 个属性
- 其次,完全随机森林是一种在属性划分时随机选择属性的树方法
- 将随机森林和完全随机森林的集成可以提高多样性,其实是一种通过参数扰动来提高d据实验只使用随机森林效果就不好

多粒度扫描(Multi-grained)
接下来介绍一下 gcForest (multi-Grained Cascade Forest)中使用的多粒度扫描。周志华表示该想法完全是受到了 CNNs/RNNs 的启发。简单的把神经网络变深来增加复杂度,譬如使用 MLP,效果就会没有 CNN、LSTM 好的原因就在于 CNN、LSTM 引入了上下文扫描的机制。
滑动窗口扫描(Sliding window scanning)
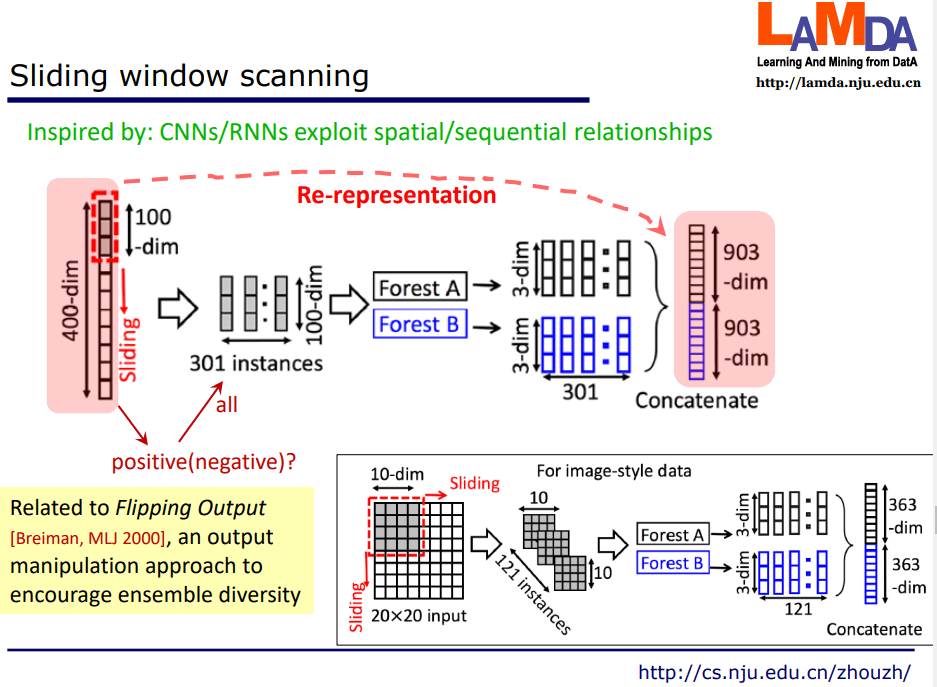 譬如对于一个 400 维的输入,我们用100维的窗口去扫描他,每次扫描产生一个样本,窗口每次向下滑动,一共可以产生 301 个 100 维样本。对于这样产生的数据集我们同样可以训练出一个森林,我们把每个样本输出的三维向量拼接起来,产生 30132=1806 维的向量。其中一个问题与技巧是,扫描产生的 100 维的样本只是原来样本的一部分,如果原来是一个正样本,我们也会将其作为正样本,这引入了严重的分类噪音。譬如我们一张图片我们判断有没有车,我们现在会把没车的部分也当作有车来训练,这不是在引入严重的分类噪音吗?这其实是用到了 Flipping Output 的机制,通过人为引入噪音,一定程度上增加了 diversity,这是一种输出扰动的方法。
譬如对于一个 400 维的输入,我们用100维的窗口去扫描他,每次扫描产生一个样本,窗口每次向下滑动,一共可以产生 301 个 100 维样本。对于这样产生的数据集我们同样可以训练出一个森林,我们把每个样本输出的三维向量拼接起来,产生 30132=1806 维的向量。其中一个问题与技巧是,扫描产生的 100 维的样本只是原来样本的一部分,如果原来是一个正样本,我们也会将其作为正样本,这引入了严重的分类噪音。譬如我们一张图片我们判断有没有车,我们现在会把没车的部分也当作有车来训练,这不是在引入严重的分类噪音吗?这其实是用到了 Flipping Output 的机制,通过人为引入噪音,一定程度上增加了 diversity,这是一种输出扰动的方法。
这样一个滑动窗口扫描产生大量样本并训练出的森林就是一个 grain。
整体结构
谈完 cascade Forest 和 Multi-grain ,接下来我们就可以把他们结合起来构成一个完整的 gcForest 了。
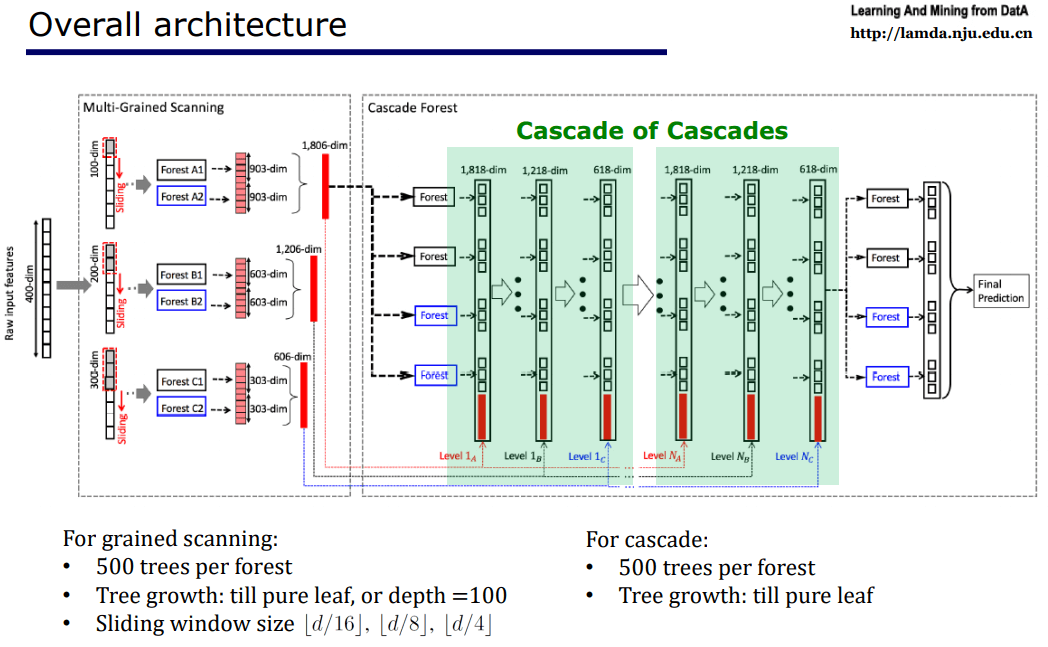
如图,假设我们有三个 grain ,其实对于原来我们说的 cascade ,每一层就对应了三级,每一级对应了三个 grain 。我们可以增加 grain 的数量,譬如把三个 grain 提升到五个 grain,性能就会有较大提升。
参数分析
gcForest 的超参数不多:
- 每个森林种树的数量
- 每棵树的深度
- grain 的数量
相比深度网络,超参数少了非常多,而且对于神经网络来说,参数调整可能有一些经验,但是经验很难并不能跨任务分享,而对于 gcForest ,实践发现在所有任务上即使采用相同的参数,效果就很好。
总结与个人感想
深度森林的成功,是 ensemble 方法的一个成功,深度森林几乎用上了所有 ensemble 方法,取得了很好的效果。gcForest 提出了一种不同于 DNNs 的深度结构,不用深度神经网络却能达到相当的效果,其实正是因为周志华老师真正深刻理解了深度神经网络的为什么有效的三个方面:逐层加工、特征变换、足够的复杂度。
共有 0 条评论