Bert 模型的使用
本文提供 另一个 html 版本。
Bert 是 Google 在 2018 年 10 月提出的一种新的语言模型,全称为 Bidirectional Encoder Representations from Transformers(Bert)。和近年来的一些语言模型譬如 ELMo 不同,BERT 通过在所有层联合调节左右两个上下文来预训练深层双向表示,此外还通过组装长句作为输入增强了对长程语义的理解。Bert 可以被微调以广泛用于各类任务,仅需额外添加一个输出层,无需进行针对任务的模型结构调整,就在文本分类,语义理解等一些任务上取得了 state-of-the-art 的成绩。
Bert 的两种用法
Bert 的论文中对预训练好的 Bert 模型设计了两种应用于具体领域任务的用法,一种是 fine-tune(微调) 方法,一种是 feature extract(特征抽取) 方法。
fine tune(微调)方法指的是加载预训练好的 Bert 模型,其实就是一堆网络权重的值,把具体领域任务的数据集喂给该模型,在网络上继续反向传播训练,不断调整原有模型的权重,获得一个适用于新的特定任务的模型。这很好理解,就相当于利用 Bert 模型帮我们初始化了一个网络的初始权重,是一种常见的迁移学习手段。
feature extract(特征抽取)方法指的是调用预训练好的 Bert 模型,对新任务的句子做句子编码,将任意长度的句子编码成定长的向量。编码后,作为你自己设计的某种模型(例如 LSTM、SVM 等都由你自己定)的输入,等于说将 Bert 作为一个句子特征编码器,这种方法没有反向传播过程发生,至于如果后续把定长句子向量输入到 LSTM 种继续反向传播训练,那就不关 Bert 的事了。这也是一种常见的语言模型用法,同类的类似 ELMo。
两种方式的适用场景
两种方法各有优劣。首先。fine tune 的使用是具有一定限制的。预训练模型的模型结构是为预训练任务设计的,所以显然的,如果我们要在预训练模型的基础上进行再次的反向传播,那么我们做的具体领域任务对网络的设计要求必然得和预训练任务是一致的。那么 Bert 预训练过程究竟在做什么任务呢?Bert 一共设计了两个任务。
任务一:屏蔽语言模型(Masked LM)
该任务类似于高中生做的英语完形填空,将语料中句子的部分单词进行遮盖,使用 [MASK] 作为屏蔽符号,然后预测被遮盖词是什么。例如对于原始句子 my dog is hairy ,屏蔽后 my dog is [MASK]。该任务中,隐层最后一层的 [MASK] 标记对应的向量会被喂给一个对应词汇表的 softmax 层,进行单词分类预测。当然具体实现还有很多问题,比如 [MASK] 会在训练集的上下文里出现,而测试集里永远没有,参见论文,此处不做详细介绍。
任务二:相邻句子判断(Next Sentence Prediction)
语料中的句子都是有序邻接的,我们使用 [SEP] 作为句子的分隔符号,[CLS] 作为句子的分类符号,现在对语料中的部分句子进行打乱并拼接,形成如下这样的训练样本:
Input = [CLS] the man went to [MASK] store [SEP] he bought a gallon [MASK] milk [SEP]
Label = IsNext
Input = [CLS] the man [MASK] to the store [SEP] penguin [MASK] are flight ##less birds [SEP]
Label = NotNext输入网络后,针对隐层最后一层 [CLS] 符号的词嵌入做 softmax 二分类,做一个预测两个句子是否是相邻的二分类任务。
可以看出,这两种任务都在训练过程中学习输入标记符号的 embedding,再基于最后一层的 embedding 仅添加一个输出层即可完成任务。该过程还可能引入一些特殊词汇符号,通过学习特殊符号譬如 [CLS] 的 embedding 来完成具体任务。
fine tune
所以,如果我们要来 fine-tune 做任务,也是这个思路:首先对原有模型做适当构造,一般仅需加一输出层完成任务。Bert 的论文对于若干种常见任务做了模型构造的示例,如下:
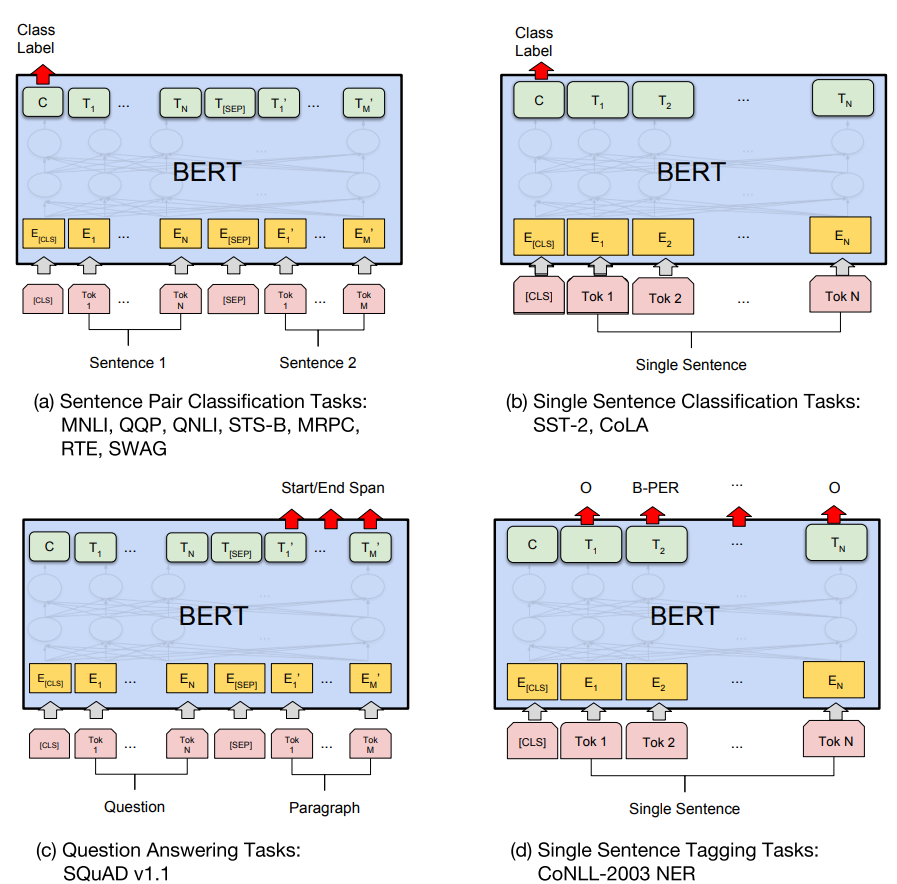
图 a 和 b 是序列级别的任务,c 和 d 是词级别的任务。a 做句子对分类任务,b 做单句分类任务,构造非常简单,将图中红色箭头指的 [CLS] 对应的隐层输出接一个 softmax 输出层。c 做的是阅读理解问题,d 做的是命名实体识别(NER),模型构造也类似,取图中箭头指出的部分词对应的隐层输出分别接一个分类输出层完成任务。
类似以上这些任务的设计,可以将预训练模型 fine-tuning 到各类任务上,但也不是总是适用的,有些 NLP 任务并不适合被 Transformer encoder 架构表示,而是需要适合特定任务的模型架构。因此基于特征的方法就有用武之地了。
feature extract
基于特征的方法和 ELMo 这类动生成态语境向量的模型是相同的使用方法:将输入序列的一层或多层的隐层状态拼接起来,作为序列的表示,然后作为下游任务模型的输入。这样带来的另一个好处是,可以把学习训练数据的表示这样一个复杂度很高的过程一次运行完成,然后基于序列的良好表示,进行大量低成本的模型实验。Bert 论文做了一些实验,对比了选取不同层数对模型性能的影响。

可以看出尽管基于 feature 的方法性能都不如全部层 fine tune 的方法,但拼接最后四个隐藏层的性能已经足够接近了。
如何 Coding?
Bert 官方提供了 tensorflow 版本的代码,可以 fine tune 和 feature extract。第三方还提供了 Pytorch 版本的代码。此外,第三方 bert-as-service 项目封装了 feature extract 的方法,能以 web 接口的形式提供句子编码服务。建议如果是 fine tune,可以采用官方项目的代码,如果是特征抽取,则可以使用 bert-as-service 项目。
以下分别介绍基于 Bert 官方代码做 fine tune,以及利用 bert-as-service 该项目做句子编码。
基于 Bert 官方代码 fine tune 做句子分类任务
下载预训练模型
预训练过程代价很高,Google 声称目前放出的 12 层的 Base 版模型是 4 块 Cloud TPU 训练四天完成的,而 24 层的 Large 版本的模型则是 16 块 TPU 训练的。由于内存不足问题,普通 GPU 例如 GTX 1080 Ti、Titan X 都不能做预训练。因此我们下载 Google 提供的 预训练模型,提供了多语版本的和中文版本的模型。
中文版的模型是由维基百科语料训练而成的,并且与英文基于词的模型不同,中文是基于字做的。
下载后解压如下,这些文件待会儿都要用到:
$ tree chinese_L-12_H-768_A-12/
chinese_L-12_H-768_A-12/
├── bert_config.json <- 模型配置文件
├── bert_model.ckpt.data-00000-of-00001
├── bert_model.ckpt.index
├── bert_model.ckpt.meta
└── vocab.txt <- 模型词汇表文件
0 directories, 5 files硬件资源要求
Google 官方表示用给定的超参对 Bert-Base 进行 fine tune 至少需要 12GB RAM。结合源码和我的测试,大概情况如下:
train_batch_size=32, max_seq_len=128, memory=11615MB
train_batch_size=32, max_seq_len=64, memory=8460MB如果想消耗更少的内存,可以减少 batch size,我目前没做更多测试。
代码纵览
下载官方的 tensorflow 版本的代码 如下:
$ tree bert
bert
├── CONTRIBUTING.md
├── create_pretraining_data.py
├── extract_features.py <- feature extract 做句子编码的例子
├── __init__.py
├── LICENSE
├── modeling.py
├── modeling_test.py
├── multilingual.md
├── optimization.py
├── optimization_test.py
├── predicting_movie_reviews_with_bert_on_tf_hub.ipynb
├── README.md
├── requirements.txt
├── run_classifier.py <- fine-tune 做句子分类的例子
├── run_classifier_with_tfhub.py
├── run_pretraining.py <- 预训练脚本
├── run_squad.py <- fine-tune 做阅读理解的例子
├── sample_text.txt
├── tokenization.py <- 分词
└── tokenization_test.py
0 directories, 20 files包含了预训练脚本以及调用预训练模型 fine-tune 做句子分类的脚本、fine-tune 做 SQuAD 任务的脚本,以及用于 feature extract 的脚本等。
run_classifier.py 是我们主要关注和修改的代码 ,这是一个句子分类的脚本,可以用来进行文本分类模型的训练(train)、评估(dev)、预测(predict)。文本分类包括单句分类,输入一个句子,给出一个类标;句子对分类,即输入两个句子,给出一个类标。run_classifier.py 将他们都封装成了同一个任务,将多个句子中间用 [SEP] 分隔符连接,因此统一成了单句分类任务。
领域分类任务
我们做一个公安领域的问题分类任务,假设数据集如下:
train.tsv
场景 问题
户政管理 我和男朋友分生的时候发现自己已经怀孕了,我想把孩子生下来,可孩子的户口怎么办
户政管理 改一下户主快不快的要几天?
出入境管理 你好,我想咨询一下:12月21日我们一家在曲靖办理了港澳通行证,当天就收到云南省公安厅出入境管理局发来的"已受理完成"的短信通知,可在12月27日我和我父亲又收到云南省公安厅出入境管理局发来的与21日相同的短信!所以想咨询一下办理港澳通行证的15个工作日是从21日还是27号开始计算时间啊?因已报团参加港澳游,所以特别急,请尽快回复,谢谢!请问我户口不在昆明,但我身份证是昆明的,是在昆明读大学的时候办的,我要办理港澳通行证,在昆明可以办理吗?还是必须要回户口所在地办理。
户政管理 想把户口迁到外省去,大概几天可以办好?
消防管理 如何预防吸烟引发的火灾?
道路交通 换领机动车登记证书,要带车一起去吗
道路交通 增加客运班线也要提出申请吗
治安管理 一般多久能把危险化学品处置方案备案管理下来
治安管理 周六能办理公章刻制备案吗?
禁毒管理 非法集资的立案金额
治安管理 娱乐场所备案申请要几天能办好
道路交通 校车标牌核发也需要到车管所吗?我们将数据划分为 train.tsv、dev.tsv、test.tsv。
定义数据读取类
run_classifier.py 声明了 DataProcessor 基类作为任务的数据处理基类,并实现了 XNLI、MultiNLI、MRPC、CoLA 这几个任务数据集的读取方式作为样例。该类很简单,仅需子类实现实现父类定义的如下四个方法:
class DataProcessor(object):
"""Base class for data converters for sequence classification data sets."""
def get_train_examples(self, data_dir):
"""Gets a collection of <code>InputExample</code>s for the train set."""
raise NotImplementedError()
def get_dev_examples(self, data_dir):
"""Gets a collection of <code>InputExample</code>s for the dev set."""
raise NotImplementedError()
def get_test_examples(self, data_dir):
"""Gets a collection of <code>InputExample</code>s for prediction."""
raise NotImplementedError()
def get_labels(self):
"""Gets the list of labels for this data set."""
raise NotImplementedError()参考写好的几个子类实现,我们首先继承 DataProcessor ,定义我们的领域分类任务的数据处理类 DomainCProcessor:
class DomainCProcessor(DataProcessor):
"""Processor for the DomainC corpus"""
pass实现 get_train_examples、get_dev_examples、get_test_examples
这三个函数,分别对应训练、开发、测试的数据集的读取,输入参数 data_dir 由脚本启动时的 data_dir 参数获得,这三个函数需要把数据集每一行数据读为一个 InputExample,所有行构成 list[InputExample]。InputExample 声明如下
class InputExample(object):
"""A single training/test example for simple sequence classification."""
def __init__(self, guid, text_a, text_b=None, label=None):
"""Constructs a InputExample.
Args:
guid: Unique id for the example.
text_a: string. The untokenized text of the first sequence. For single
sequence tasks, only this sequence must be specified.
text_b: (Optional) string. The untokenized text of the second sequence.
Only must be specified for sequence pair tasks.
label: (Optional) string. The label of the example. This should be
specified for train and dev examples, but not for test examples.
"""
self.guid = guid
self.text_a = text_a
self.text_b = text_b
self.label = labelInputExample 仅由唯一id、句子a、句子b、类标,这四个属性构成,对于单句任务,句子 b 置 None。
所以我们要保证这三个函数 return 值是下面这样的形式即可:
return [
InputExample('0', '想把户口迁到外省去,大概几天可以办好?', None, '户政管理'),
InputExample('1', '校车标牌核发也需要到车管所吗?', None, '道路交通'),
# ...
]一个完整的实现如下:
class DomainCProcessor(DataProcessor):
def get_train_examples(self, data_dir):
return self._create_examples(
self._read_tsv(os.path.join(data_dir, "train.tsv")), "train")
def get_dev_examples(self, data_dir):
return self._create_examples(
self._read_tsv(os.path.join(data_dir, "dev.tsv")), "dev")
def get_test_examples(self, data_dir):
return self._create_examples(
self._read_tsv(os.path.join(data_dir, "test.tsv")), "test")
@classmethod
def _read_tsv(cls, input_file, quotechar=None):
"""读取 tsv 的工具方法"""
with tf.gfile.Open(input_file, "r") as f:
reader = csv.reader(f, delimiter="\t", quotechar=quotechar)
lines = []
for line in reader:
lines.append(line)
return lines
def _create_examples(self, lines, set_type):
"""创建 InputExample 对象的工具方法"""
examples = []
for (i, line) in enumerate(lines):
if i == 0:
continue
guid = "%s-%s" % (set_type, i)
text_a = tokenization.convert_to_unicode(line[1])
if set_type == "test": # 对于测试集,去除真实标记
label = "上网服务管理"
else:
label = tokenization.convert_to_unicode(line[0])
examples.append(
InputExample(guid=guid, text_a=text_a, text_b=None, label=label))
return examples
def get_labels(self):
return ["上网服务管理", "出入境管理", "刑事案件管辖", "户政管理", "治安管理", "消防管理", "禁毒管理", "道路交通"]训练
一旦定义好数据读取类,就可以训练模型了。启动命令如下:
BERT_BASE_DIR=/bert/chinese_L-12_H-768_A-12
python run_classifier.py \
--task_name=DomainC \
--do_train=true \
--do_eval=true \
--do_predict=false \
--data_dir='/bert/data/domainc' \
--vocab_file=$BERT_BASE_DIR/vocab.txt \
--bert_config_file=$BERT_BASE_DIR/bert_config.json \
--init_checkpoint=$BERT_BASE_DIR/bert_model.ckpt \
--max_seq_length=128 \
--train_batch_size=32 \
--learning_rate=2e-5 \
--num_train_epochs=3.0 \
--output_dir=/tmp/domainc_output/参数中 do_train、do_eval 都是 true,因此会在 train.tsv 上训练,dev.tsv 上评估模型效果。至于 predict,我们下一节介绍。
其中的超参,官方表示如下设定在所有任务上都表现很好:
• Batch size: 16, 32
• Learning rate (Adam): 5e-5, 3e-5, 2e-5
• Number of epochs: 3, 4训练完毕,可以看到输出评估结果如下:
INFO:tensorflow:***** Eval results *****
INFO:tensorflow: eval_accuracy = 0.9213818
INFO:tensorflow: eval_loss = 0.18872626
INFO:tensorflow: global_step = 4721
INFO:tensorflow: loss = 0.1886153推断
run_classifier.py 主要设计为单次运行的目的,如果把 do_predict 参数设置成 True,倒也确实可以预测,但输入样本是基于文件的,并且不支持将模型持久化在内存里进行 serving,因此需要自己改一些代码,达到两个目的:
- 1.允许将模型加载到内存里。允许一次加载,多次预测。
- 2.允许读取非文件中的样本进行预测。譬如从标准输入流读取样本输入。
将模型加载到内存里
run_classifier.py 的 859 行加载了模型为 estimator 变量,但是遗憾的是 estimator 原生并不支持一次加载,多次预测。参见:https://guillaumegenthial.github.io/serving-tensorflow-estimator.html。
因此需要使用 estimator.export_saved_model() 方法把 estimator 重新导出成 tf.saved_model。
代码如下(参考了 https://github.com/bigboNed3/bert_serving):
def serving_input_fn():
label_ids = tf.placeholder(tf.int32, [None], name='label_ids')
input_ids = tf.placeholder(tf.int32, [None, FLAGS.max_seq_length], name='input_ids')
input_mask = tf.placeholder(tf.int32, [None, FLAGS.max_seq_length], name='input_mask')
segment_ids = tf.placeholder(tf.int32, [None, FLAGS.max_seq_length], name='segment_ids')
input_fn = tf.estimator.export.build_raw_serving_input_receiver_fn({
'label_ids': label_ids,
'input_ids': input_ids,
'input_mask': input_mask,
'segment_ids': segment_ids,
})()
return input_fn
estimator._export_to_tpu = False
estimator.export_savedmodel('/bert/my_model', serving_input_fn)执行后,可以
$ ls /bert/my_model
1553914434会有一个时间戳命名的模型目录,因此我们最终的模型目录为 /bert/my_model/1553914434。
这样之后我们就不需要第 859 行那个 estimator 对象了,可以自行从刚刚的模型目录加载模型:
predict_fn = tf.contrib.predictor.from_saved_model('/bert/my_model/1553914434')从内存中读取样本数据并预测
基于上面的 predict_fn 变量,就可以直接进行预测了。下面是一个从标准输入流读取问题样本,并预测分类的样例代码:
while True:
question = input("> ")
predict_example = InputExample("id", question, None, '某固定伪标记')
feature = convert_single_example(100, predict_example, label_list,
FLAGS.max_seq_length, tokenizer)
prediction = predict_fn({
"input_ids":[feature.input_ids],
"input_mask":[feature.input_mask],
"segment_ids":[feature.segment_ids],
"label_ids":[feature.label_id],
})
probabilities = prediction["probabilities"]
label = label_list[probabilities.argmax()]
print(label)基于 bert-as-service 项目 feature extract
bert-as-service 是一个第三方项目,Github 地址: hanxiao/bert-as-service。可以对 Bert 实现 feature extract的用法,即将一个不定长的句子编码为一个定长的向量。该项目对 Bert 官方代码封装实现了 web 后端,以 web 接口的形式提供句子编码服务。
一些问题
这个项目做的不是很完善,譬如 bert-as-service 分为服务端和客户端。官方文档中服务端部署在 GPU 上、客户端则在 CPU 上。虽然官方没有直接提到,但是事实上服务端部署在 CPU 也可以。但其官方 docker 脚本并不能在 CPU 上运行,需要自行修改基容器。
其次,文档声称tensorflow>=1.10,python>=3.5即可运行,但事实上我在 windows 运行失败,大概是有 bug。
搭建服务端
搭建之前需要准备好上文 下载预训练模型 提到的 Bert 预训练模型。
安装并启动 bert-as-service。启动参数包括模型路径 PATH_MODEL、进程数 NUM_WORKER。安装方式有 pip 或 docker:
pip (CPU/GPU)
PATH_MODEL=/tmp/chinese_L-12_H-768_A-12
NUM_WORKER=4
pip install bert-serving-server
bert-serving-start -model_dir $PATH_MODEL -num_worker=$NUM_WORKERdocker
GPU
git clone https://github.com/hanxiao/bert-as-service.git
cd bert-as-service
docker build -t bert-as-service -f docker/Dockerfile .
PATH_MODEL=/tmp/chinese_L-12_H-768_A-12
NUM_WORKER=4
docker run --runtime nvidia --name bert-as-service -dit -p 5555:5555 -p 5556:5556 -v $PATH_MODEL:/model -t bert-as-service $NUM_WORKERCPU
git clone https://github.com/hanxiao/bert-as-service.git
cd bert-as-service
sed -i 's/tensorflow:1.12.0-gpu-py3/tensorflow:1.12.0-py3/g' docker/Dockerfile
docker build -t bert-as-service -f docker/Dockerfile .
PATH_MODEL=/tmp/chinese_L-12_H-768_A-12
NUM_WORKER=4
docker run --name bert-as-service -dit -p 5555:5555 -p 5556:5556 -v $PATH_MODEL:/model -t bert-as-service $NUM_WORKER客户端调用
安装客户端库。
pip install bert-serving-client安装完就可以在代码中调用了:
>>> from bert_serving.client import BertClient
>>> bc = BertClient(ip='192.168.11.42')
>>> bc.encode(['合同诈骗罪是怎样处罚的?', '孩子办户口的时间限制'])
array([[ 0.56223714, -0.28043476, 0.15880957, ..., -0.5312789 ,
-0.05316753, 0.5204646 ],
[ 0.3173091 , -0.39072016, 0.08520816, ..., -0.21686065,
-0.25086305, -0.08226559]], dtype=float32)
>>>如上,encode 函数接受句子 list,无论句子有多少,服务端会自动处理 batch。获得了句子的编码之后,就可以输入自己的模型做后续运算了。
你好,请问从内存载入训练好的模型后,probabilities = prediction[“probabilities”] 中的probabilities是在哪里定义的呢?求指教(因为看不到完整的代码T.T)
你好,在这里:https://github.com/google-research/bert/blob/f39e881b169b9d53bea03d2d341b31707a6c052b/run_classifier.py#L704
你好,我自己测试,从正常的estimator.predict 变成 tf.contrib.predictor.from_saved_model 后,每条数据平均的预测时间变长了。是就应该时间变长吗??
应该是正常的,单条预测速会慢,批量组成batch输入平均每条会更快。
你好,请问一下,按您描述的方法保存的pb模型,当我加载此模型,给模型输入一个样本,如何利用这个模型获取该样本在某一层的输出呢(也就是样本在某层的特征),
需要修改model_fn_builder,在其中返回每一层的表示,然后就可以像probabilities = prediction[“probabilities”]取出概率一样取出某一层了:
predictions["layer_output_%d" % i],具体参考google官方的bert/extract_features.py有详细的写法:https://github.com/google-research/bert/blob/f39e881b169b9d53bea03d2d341b31707a6c052b/extract_features.py#L194您好,我在编写的flask接口中加载tf.contrib.predictor.from_saved_model模型,感觉每次访问接口的时候,都要重新加载一次模型,没有实现一次加载,多次预测
你把tf.contrib.predictor.from_saved_model这个函数调用一次并用一个变量保存在全局譬如main里或者非函数区域,然后在flask的具体路由里调用即可,这样模型就不会被加载多次了
https://padeoe.com/bert-model-serving/
你好,请问get_test_examples里也要输入标签吗?这个标签对预测结果是否有影响?
没有影响的,仅用于训练完毕后测试
因为我用的是比赛数据,所以是不提供测试集label的
您好,我是bert新手,我想使用pytorch-pretrained-bert这个第三方提供的库,使用自己的数据进行finetune,微调任务为QA任务和句子队分类任务,但是看了手册却无从下手,不知如何进行finetune,是否跟pytorch的微调方式是一样的。有点糊涂~谢谢你查看我的评论,如果能提供一些帮助就更好啦,电子邮箱已经提供,感谢您